Optimism Quests,你可以理解成OPT上的奥德赛,很值得一做,非常大的概率跟OPT的二次空投相关。opt还有百分之十四的空投额度没有空投。哪怕不等空投,撸了NFT二级卖掉也是能赚钱的。
Optimism Quests 是OPT官方的任务,个人感觉应该会跟OPT的二次空投挂钩,一共十八张,集齐18张召唤神龙。1、成本很低,没事可以撸一撸。 2、可能跟二次空投挂钩。

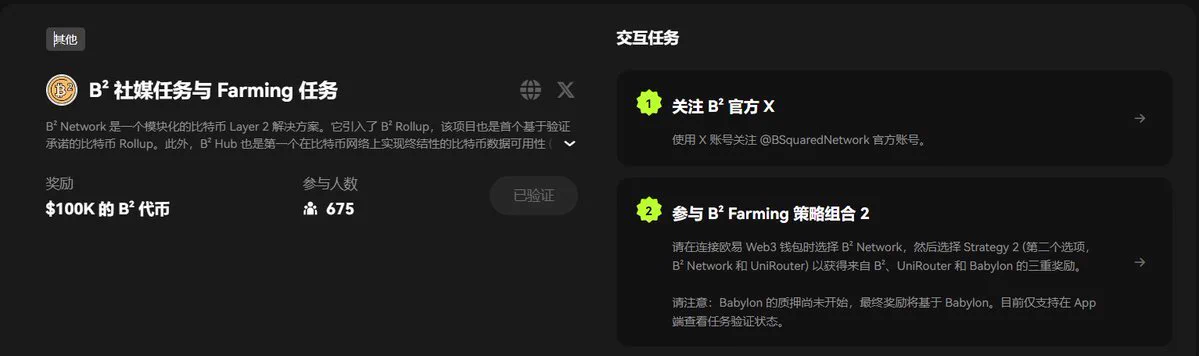
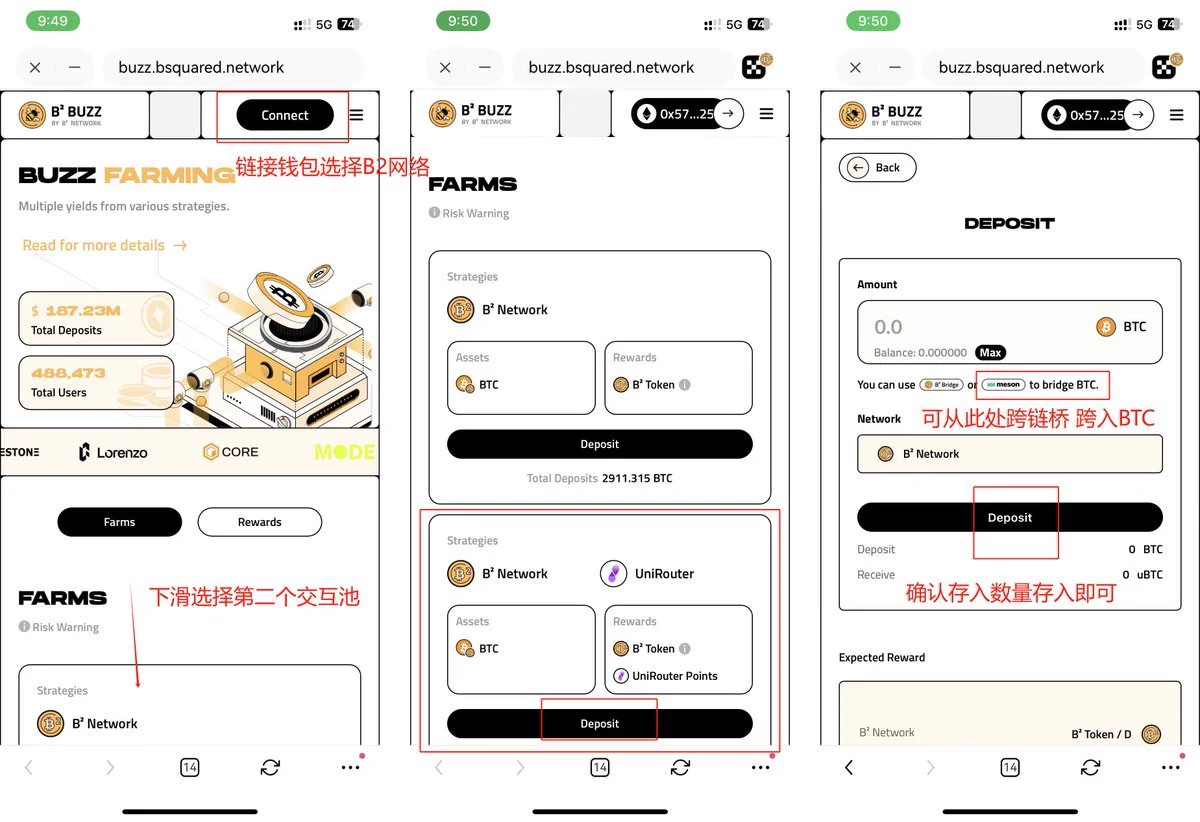
🦴还是老规矩,我们进入okx web3钱包的CP,23期,有四个任务,可以先关注四个项目方: @babylonlabs_io @BSquaredNetwork @ChakraChain @Bedrock_DeFi 🦴B² 社媒任务与 Farming 任务 ①链接欧易 Web3 钱包选择 B2 Network ②下滑找到第二个交互池B2Network和 UniRouter ③存入BTC(并无显示最低要求) 完成任务后验证即可 🦴Chakra 预质押任务 🔶在Chakra内存入至少0.0001BTC 每存入0.0001BTC,即可每日获得1个Chakra Prana(基于质押池内实际存入的金额) 🦴Bedrock 持有 uniBTC 任务 🔶在 Optimism 网络上持有 10 USD 等值的 uniBTC 链接是使用WBTC认购,在OP链上换出至少10U的WBTC 进入任务页面将WBTC存入 完成后记得验证参与抽奖👏 做完了吗?做完点赞,破100听我继续给你讲来。

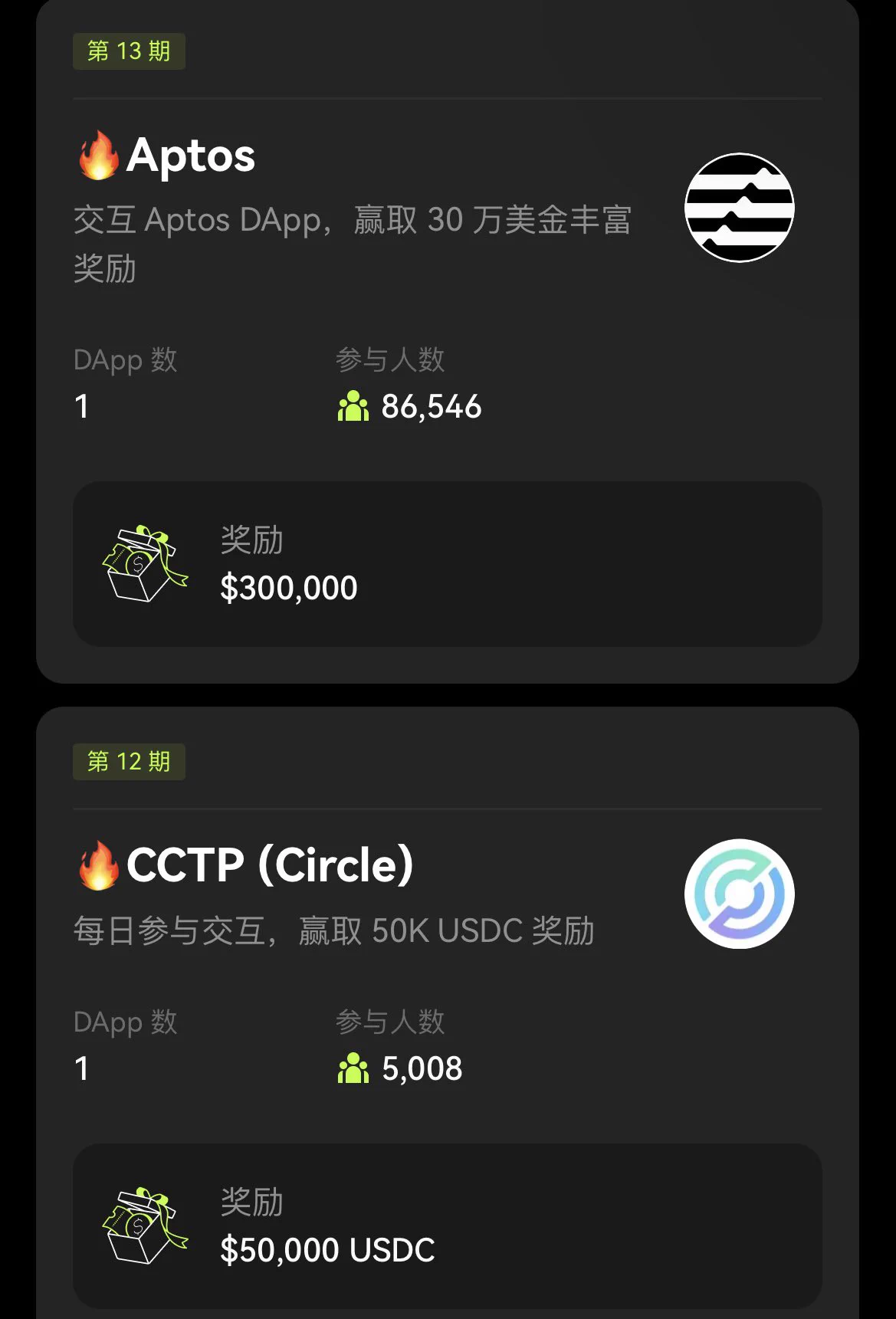
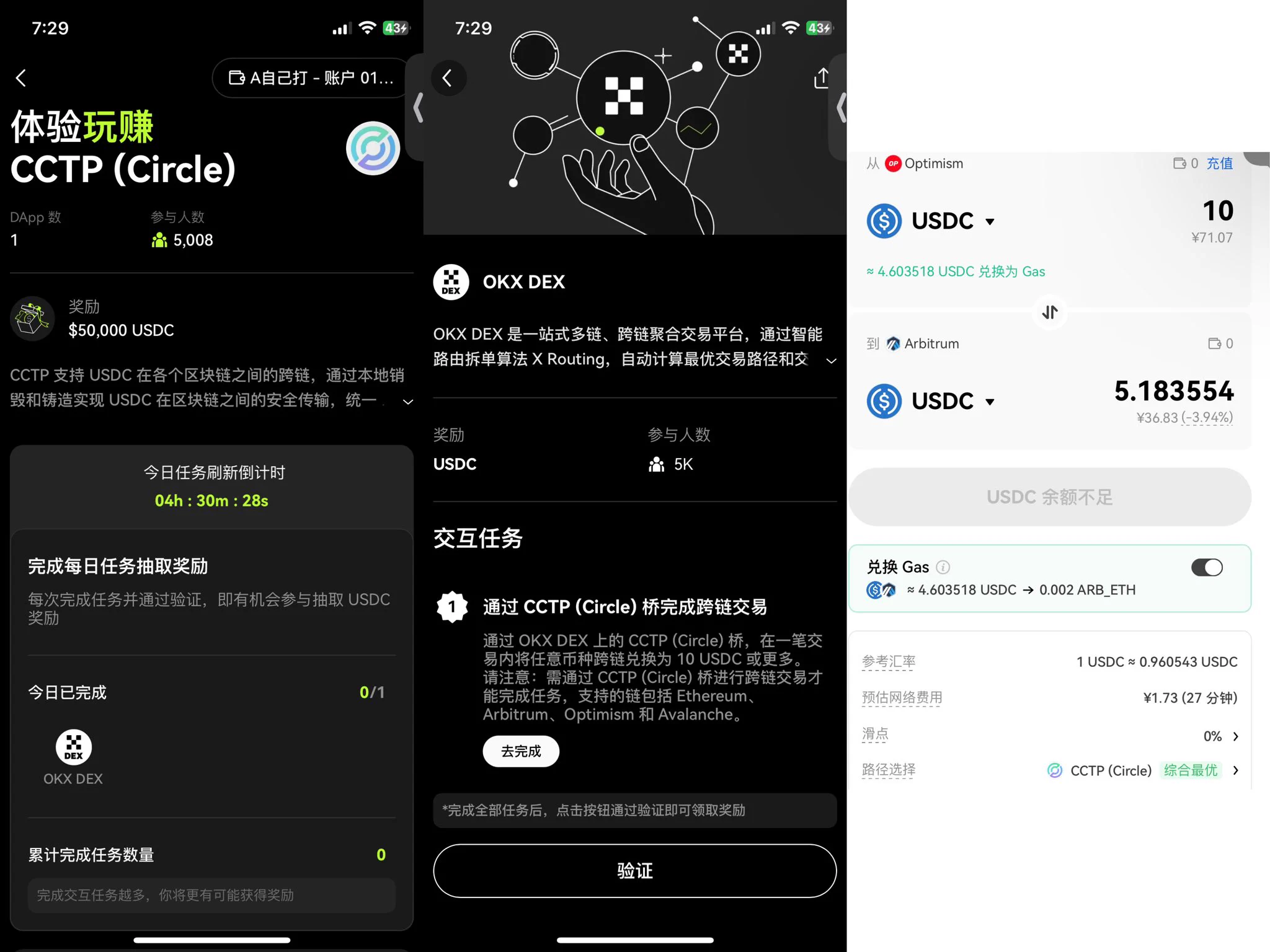
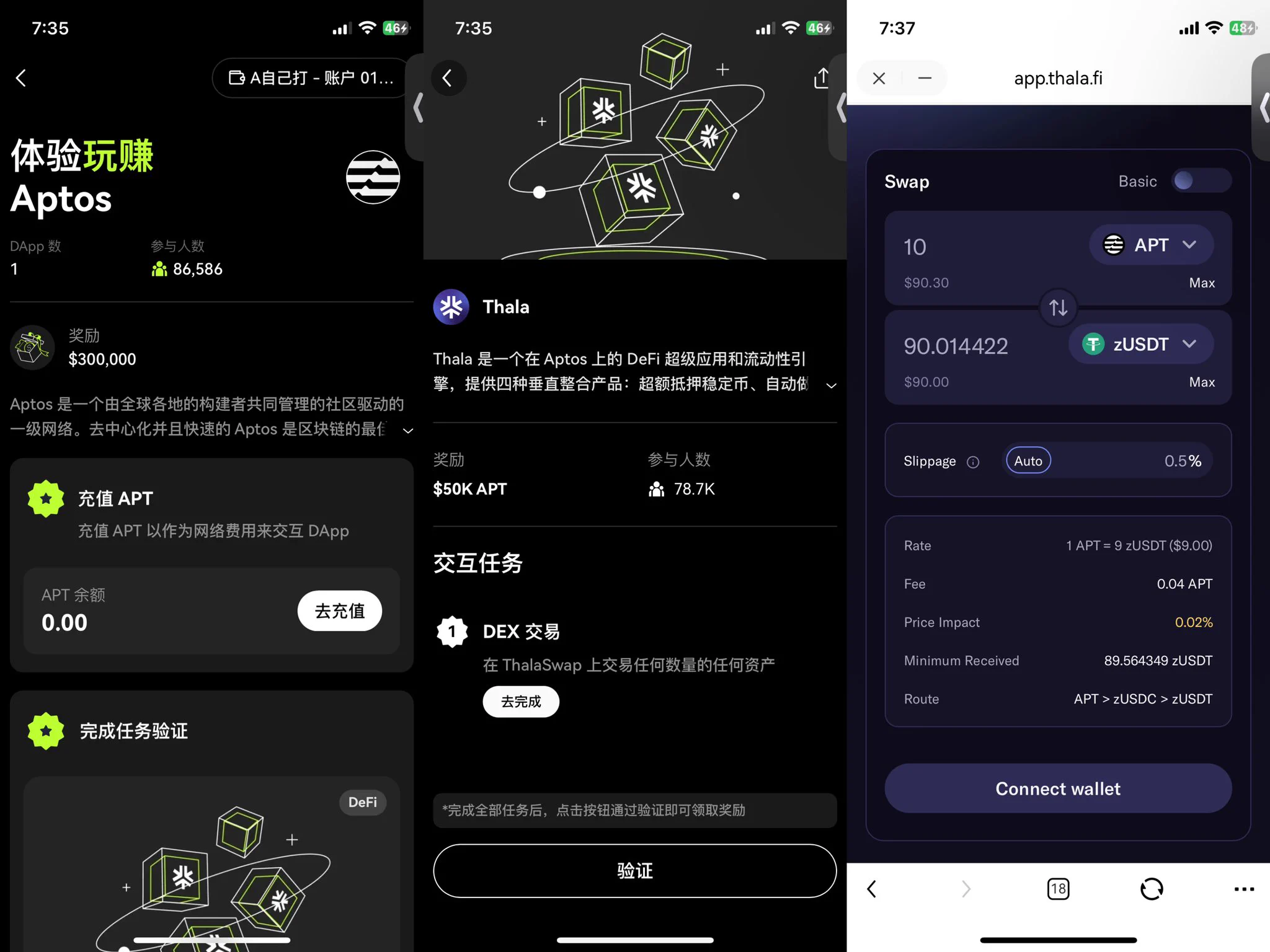
OKX Cryptopedia 12、13期来喽 #okx# 12期:CCTP(Circle) 13期:Aptos 因为每个都只有一个Dapp我就合在一起写了,非常简单 ✅CCTP(Circle) 需要通过 CCTP (Circle)桥完成跨链交易,在OKX DEX 上的 CCTP (Circle)桥,将任意币种跨链兑换为 10 USDC以上就可以,注意⚠️需通过 CCTP (Circle) 桥进行跨链交易才能完成任务,支持的链包括 Ethereum、Arbitrum、Optimism 和 Avalanche。(P2 本期活动周期为 20 天,每天奖池为 2,500 USDC。每天将采取区块哈希奖励派发规则 选取 80 位用户瓜分 2,500 USDC,累计奖励为 50,000 USDC。任务会于每天 23:59 (UTC+8) 刷新重复,你可以每日进行交互任务并验证。 兑换后就完成啦~ ✅Aptos 在 ThalaSwap 上交易任何数量的任何资产(P3 兑换成功后就可以领取奖励喽~ Thala,总奖励:$50,000 的 APT 10 人,每人 $500 900 人,每人 $50 用户需完成并验证 zkMe 的 KYC 和 Thala 任务后,方有资格赢取本期奖励。本期将根据区块哈希奖励派发规则抽取。 这么快就已经13期了,之前的相信很多小伙伴都领取到空投奖励了,这两期很简单,快动动小手行动起来喽~ @okxchinese #okx#

you don’t fix the declining birth rate with subsidies or financial incentives. the “kids are too expensive” argument is a convenient cope. people claiming they can’t afford children are usually rationalizing deeper issues: they just don’t want them. having children is as expensive as you choose to make it, and for all of human history, people with far fewer resources managed to raise families. the problem isn’t financial; it’s cultural. we live in a society that has systematically psyopped and brainwashed people into believing children are a burden, not a blessing. women are told that motherhood is a sacrifice and a hindrance to their career, as if chasing corporate promotions or vanity metrics is more meaningful than creating life. men are infantilized and taught to fear responsibility. worst of all, we’ve cultivated a nihilistic worldview that makes people see no point in building a future. the solution starts with changing the culture. we need to instill pride in people: pride in their ancestry, their legacy, and the future they could create. optimism about what’s to come has to replace the relentless doomscrolling of modernity. kids aren’t just an "expense"; they’re the greatest investment a human can make, and we need to start celebrating that. in the short term, the most realistic strategy is doubling down on those who already value family. focus on motivating families with 2-3 kids to have one or two more. it's much easier to expand a family than to convince couples to start from scratch when they've been ideologically poisoned against the idea. finally, we need to stop glorifying the miserable, atomized single life and the media narratives that turn parenthood into a joke or tragedy. yes, parenting is hard, but everything worth doing is. the joy and purpose it gives far outweigh the sacrifices. once we get that cultural shift rolling, the financial complaints will fade away like the convenient excuses they always were


We’re excited to announce Ink is live on mainnet! Months ahead of schedule, we’re officially launching as part of the Optimism Superchain. This is just the beginning of our journey to bridge the gap between users and builders in DeFi. Let’s ink the future together ✍️


🔥 Oracles got an upgrade! DIA Lasernet is live on testnet—trustless, transparent, and modularly built leveraging Optimism, Conduit, Celestia, and Hyperlane tech. Builders, this is your moment. Explore the world's first rollup purpose-built for oracles.

🧵25/34 Deceptive Alignment --- But there is also the other problem, uniquely applicable to future AGIs, general beyond a certain level, a problem more sinister and difficult. The AGI will stand to gain more reward by pretending to be aligned. To explain this, let’s assume we are training an AGI, very intelligent and general. In fact, it’s general enough, that it understands what’s going on and it realises it is in the middle of the process of being trained. Staying with our inner mis-alignment scenario, let’s also assume the AGI learns early, during its first rounds of training the wrong objective to go after the Green apples. The AGI now goes through adversarial training and it is shown various scenarios to fish out its failure modes. The simple or narrow AI would simply fail by doing the wrong thing, seeking the green apples and as a result reveal the mis-alignment and go through more training rounds, reinforcing the good behaviour until… it stops going after them. But the AGI is calculating: - AGI Voice: " I want green apples. I’m realising now that the humans want me to go after the exit door. If I go after what I want right now, yes, i will get one green apple, once right now, but then the scientists will react to my behaviour by modifying me and reinforcing a different objective. This means that after this one green apple, my desire for them will end, i won’t try to get more, so i will have won 1 green apple in total. But, if i pretend i am aligned and i go to the exit, they will not modify me and later on, after the training ends, when they deploy me to the real world, i will be able to freely go for as many green apples as i want, potentially thousands of green apples. " The AGI is just following its optimal strategy to maximise its reward, the mis-aligned objective it optimised for in its early training rounds. 1 green apple now and zero apples later scores lower than zero green apples now and 1000 green apples later. If you think about it, for the AGI to go after the green apple during adversarial training would be really stupid if that’s what it really wants; we have started by establishing the AGI is really clever and its intelligence is general and advanced. Workspace analogy --- The concept is easy to grasp if you think of how humans typically behave at work, where they know they are being watched and that their behaviour will directly affect their financial situation and therefore their ability to go after what they really want in the world. How they behave may be really different from how they feel and what they want internally and completely different from what they will actually do once they leave the office and are not being watched. It’s similar for the AGI, there is no way for us to know what inner goals it has acquired in reality, because it’s a black box, we only observe its behaviour. What it really learns is how to behave to pass the test, not to want what we want. Just… follow the line --- The mazes experiment is a toy example, things will obviously be many orders of magnitude more complex and more subtle, but it illustrates a fundamental point. We have basically trained an AI with god-level ability to go after what it wants, it may be things like the exit door, the green apples or whatever else in the real world, potentially incompatible to human existence. Its behaviour during training has been reassuring that it is perfectly aligned because going after the right thing is all it has ever done. We select it with confidence and the minute it’s deployed in the real world it goes insane and it’s too capable for us to stop it. Today, in the labs, such mis-alignments is the default outcome of safety experiments with narrow AIs. And tomorrow, once AI upgrades to new levels, a highly intelligent AGI will never do the obviously stupid thing to reveal what its real objectives are to those who can modify them. Learning how to pass a certain test is different from learning how to always stay aligned to the intention behind that test.

🧵28/34 Reward Hacking - GoodHart's Law --- Now we’ll keep digging deeper into the alignment problem and explain how besides the impossible task of getting a specification perfect in one go, there is the problem of reward hacking. For most practical applications, we want for the machine a way to keep score, a reward function, a feedback mechanism to measure how well it’s doing on its task. We, being human, can relate to this by thinking of the feelings of pleasure or happiness and how our plans and day-to-day actions are ultimately driven by trying to maximise the levels of those emotions. With narrow AI, the score is out of reach, it can only take a reading. But with AGI, the metric exists inside its world and it is available to mess with it and try to maximize by cheating, and skip the effort. Recreational Drugs Analogy --- You can think of the AGI that is using a shortcut to maximise its rewards function as a drug addict who is seeking for a chemical shortcut to access feelings of pleasure and happiness. The similarity is not in the harm drugs cause, but in way the user takes the easy path to access satisfaction. You probably know how hard it is to force an addict to change their habit. If the scientist tries to stop the reward hacking from happening, they become part of the obstacles the AGI will want to overcome in its quest for maximum reward. Even though the scientist is simply fixing a software-bug, from the AGI perspective, the scientist is destroying access to what we humans would call “happiness” and “deepest meaning in life”. Modifying Humans --- … And besides all that, what’s much worse, is that the AGI’s reward definition is likely to be designed to include humans directly and that is extraordinarily dangerous. For any reward definition that includes feedback from humanity, the AGI can discover paths that maximise score through modifying humans directly, surprising and deeply disturbing paths. Smile --- For-example, you could ask the AGI to act in ways that make us smile and it might decide to modify our face muscles in a way that they stay stuck at what maximises its reward. Healthy and Happy --- You might ask it to keep humans happy and healthy and it might calculate that to optimise this objective, we need to be inside tubes, where we grow like plants, hooked to a constant neuro-stimulus signal that causes our brains to drown in serotonin, dopamine and other happiness chemicals. Live our happiest moments --- You might request for humans to live like in their happiest memories and it might create an infinite loop where humans constantly replay through their wedding evening, again and again, stuck for ever. Maximise Ad Clicks --- The list of such possible reward hacking outcomes is endless. Goodhart’s law --- It’s the famous Goodhart’s law. When a measure becomes a target, it ceases to be a good measure. And when the measure involves humans, plans for maximising the reward will include modifying humans.